質問 1:After migrating to PowerHA 7 and restarting the cluster for the first time, the following error is reported:
Starting Cluster Services on node: Jessica
This may take a few minutes. Please wait...
Jessica: cl_rsh had exit code = 13, see cspoc.log and/or clcomd.log for more information
What is the most common cause of this error?
A. The hacmp group does not have proper permissions or ID number.
B. Last C-SPOC operation failed.
C. /etc/cluster/rhosts is incorrectly configured.
D. CAA cluster services are not running.
正解:C
質問 2:An administrator performed a DARE operation in their cluster configuration. During this operation one of the cluster nodes halted. The node halt was an isolated problem, however, as a result the DARE operation did not complete.
When the failed node was re-integrated to the cluster, the following error was received when trying to perform the DARE operation again:
cldare: A lock for a Dynamic Reconfiguration event has been detected.
Which action will resolve the problem?
A. Remove the file cldare_lock in /usr/es/sbin/cluster/etc/objrepos/staging and re-try the DARE operation.
B. Use the PowerHA problem determination function to "Release Locks Set By Dynamic Reconfiguration" and re-try the DARE operation
C. Verify and synchronize the cluster with "Automatically correct errors found during verification" set to "yes" which will complete the DARE operation.
D. Perform the PowerHA problem determination function to "Restore HACMP Configuration Database from Active Configuration" which will complete the DARE operation.
正解:B
質問 3:An administrator has a 2-node cluster and has chosen the C-SPOC option to bring a resource group offline. The resource group was stable on the primary node prior taking resource offline, however it has gone into an error state. The administrator corrects the error and issues the clruncmd to continue cluster processing.
What will happen to the resource group?
A. The resource group falls over to the remaining active node.
B. The node shuts down and the resource group goes into temporary error state.
C. The resource group remains in error state until services on all cluster nodes are stopped and restarted.
D. The resource group goes offline.
正解:D
質問 4:Which tasks will create and vary on a new volume group for an existing resource group in a 2node cluster?
A. Create a newvolume group using mkvg command on node1 and run importvg on node2 Run PowerHA SMIT Menu "Import a Volume Group" to import the volume group for the resource group
B. Create a new volume group for the resource group using PowerHA SMIT Menu "Create a Volume Group" on node1 Run PowerHA SMIT Menu "Verify and Synchronize Cluster Configuration"
C. Create a new volume group for the resource group using cl_mkvg command with C-SPOC option on node1 Run PowerHA SMIT Menu "Synchronize a Volume Group Definition"
D. Create a new volume group for the resource group using PowerHA SMIT Menu "Configure Storage Resources" on node1 Run PowerHA SMIT Menu "Synchronize a Volume Group Definition"
正解:B
質問 5:The /usr/es/sbin/cluster/netmon.cf file contains the following lines:
IREQD host1.ibm 100.12.7.9
IREQD host1.ibm host4.ibm
What is the effect of this configuration?
A. The node will only be considered "up" if it can ping at least one address on each line.
B. The interface will only be considered "up" if it can ping 100.12.7.9 AND the address to which host4.ibm resolves.
C. The node will only be considered "up" if it can ping all addresses on the first line AND all addresses on the second line
D. The interface will only be considered "up" if it can ping 100.12.7.9 OR the address to which host4.ibm resolves.
正解:D
質問 6:If an application stop script fails during selective failover process, which action will recover the production service as soon as possible?
A. Force shutdown all nodes in the cluster for data integrity.
B. Halt the node on which application stop script has failed.
C. Wait for time-out via config_too_long event.
D. Select "Recover From HACMP Script Failure" from SMIT
正解:B
質問 7:An administrator was unable to contact NodeB, and on further investigation he found that the node was not active. The other cluster node (NodeA) is active. After restarting the node, the following entries are found in errpt: What caused NodeB to halt?
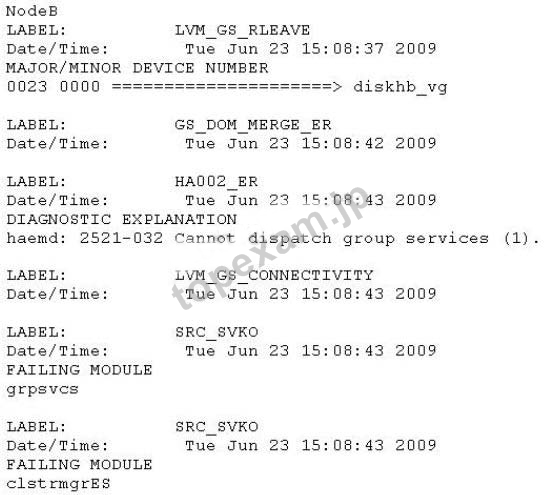 A.
A. clstrmgrES was killed on NodeB
B. gsclvmd was killed on NodeB
C. Group Services domain became partitioned, then dissolved on reactivation
D. diskhb_vg was forced offline which caused a diskhb network failure and the cluster was partitioned
正解:C
質問 8:Which operation can be done by DARE?
A. Change failover policy of resource group
B. Change cluster name
C. Change node name
D. Change application server name
正解:D
TopExamは君に000-332の問題集を提供して、あなたの試験への復習にヘルプを提供して、君に難しい専門知識を楽に勉強させます。TopExamは君の試験への合格を期待しています。
安全的な支払方式を利用しています
Credit Cardは今まで全世界の一番安全の支払方式です。少数の手続きの費用かかる必要がありますとはいえ、保障があります。お客様の利益を保障するために、弊社の000-332問題集は全部Credit Cardで支払われることができます。
領収書について:社名入りの領収書が必要な場合、メールで社名に記入していただき送信してください。弊社はPDF版の領収書を提供いたします。
弊社は無料IBM 000-332サンプルを提供します
お客様は問題集を購入する時、問題集の質量を心配するかもしれませんが、我々はこのことを解決するために、お客様に無料000-332サンプルを提供いたします。そうすると、お客様は購入する前にサンプルをダウンロードしてやってみることができます。君はこの000-332問題集は自分に適するかどうか判断して購入を決めることができます。
000-332試験ツール:あなたの訓練に便利をもたらすために、あなたは自分のペースによって複数のパソコンで設置できます。
弊社のIBM 000-332を利用すれば試験に合格できます
弊社のIBM 000-332は専門家たちが長年の経験を通して最新のシラバスに従って研究し出した勉強資料です。弊社は000-332問題集の質問と答えが間違いないのを保証いたします。

この問題集は過去のデータから分析して作成されて、カバー率が高くて、受験者としてのあなたを助けて時間とお金を節約して試験に合格する通過率を高めます。我々の問題集は的中率が高くて、100%の合格率を保証します。我々の高質量のIBM 000-332を利用すれば、君は一回で試験に合格できます。
弊社は失敗したら全額で返金することを承諾します
我々は弊社の000-332問題集に自信を持っていますから、試験に失敗したら返金する承諾をします。我々のIBM 000-332を利用して君は試験に合格できると信じています。もし試験に失敗したら、我々は君の支払ったお金を君に全額で返して、君の試験の失敗する経済損失を減少します。
一年間の無料更新サービスを提供します
君が弊社のIBM 000-332をご購入になってから、我々の承諾する一年間の更新サービスが無料で得られています。弊社の専門家たちは毎日更新状態を検査していますから、この一年間、更新されたら、弊社は更新されたIBM 000-332をお客様のメールアドレスにお送りいたします。だから、お客様はいつもタイムリーに更新の通知を受けることができます。我々は購入した一年間でお客様がずっと最新版のIBM 000-332を持っていることを保証します。
IBM High Availability for AIX - Technical Support and Administration -v2 認定 000-332 試験問題:
1. A 2-node PowerHA 6 cluster has Ethernet and RS232 heartbeat networks.
The RS232 connection fails What is the effect of losing the RS232 heartbeat connection?
A) An RS232 heartbeat network down event is recorded.
B) The Ethernet heartbeat interval is reduced.
C) Cluster services are stopped on affected nodes.
D) All network heartbeats are lost.
2. A PowerHA 6 cluster uses IPAT with aliasing and disk heartbeat. The administrator noticed the standby node crashes during a failover test. There are entries related to the Dead Man Switch (DMS) timeout in the AIX error log.
Which action is recommended to reduce the risk of DMS timeouts?
A) Dedicate a set of disks for disk heartbeat and set failure detection rate to delay.
B) Set Failure detection rate of diskhb network module to slow.
C) Create a RS232 heartbeat and set failure detection rate to delay.
D) Set Failure detection rate of Ethernet to normal.
3. In a PowerHA 6 environment, what is recommended to ensure I/O disk-write buffers are flushed and to reduce chance of deadman switch timeouts?
A) Change all cluster node disks "hcheck_Interval" attributes to 60 Seconds
B) Configure fast failure detection on shared disks
C) Change "syncd" frequency to 10 seconds
D) Set the CAA timeout parameter to "auto"
4. During a rolling migration to PowerHA 7, when is the Cluster Aware AIX (CAA) cluster created?
A) After upgrading AIX on last node
B) After running clmigcheck on the last node
C) After the first synchronization of the upgraded cluster
D) After starting cluster services on the last node
5. Which command will display the current location for all resource groups within a cluster?
A) cllsres
B) cIRGinfo
C) cl_finders
D) clshowres
質問と回答:
質問 # 1
正解: A | 質問 # 2
正解: B | 質問 # 3
正解: C | 質問 # 4
正解: B | 質問 # 5
正解: B |


 PDF版 Demo
PDF版 Demo




 品質保証TopExamは我々の専門家たちの努力によって、過去の試験のデータが分析されて、数年以来の研究を通して開発されて、多年の研究への整理で、的中率が高くて99%の通過率を保証することができます。
品質保証TopExamは我々の専門家たちの努力によって、過去の試験のデータが分析されて、数年以来の研究を通して開発されて、多年の研究への整理で、的中率が高くて99%の通過率を保証することができます。 一年間の無料アップデートTopExamは弊社の商品をご購入になったお客様に一年間の無料更新サービスを提供することができ、行き届いたアフターサービスを提供します。弊社は毎日更新の情況を検査していて、もし商品が更新されたら、お客様に最新版をお送りいたします。お客様はその一年でずっと最新版を持っているのを保証します。
一年間の無料アップデートTopExamは弊社の商品をご購入になったお客様に一年間の無料更新サービスを提供することができ、行き届いたアフターサービスを提供します。弊社は毎日更新の情況を検査していて、もし商品が更新されたら、お客様に最新版をお送りいたします。お客様はその一年でずっと最新版を持っているのを保証します。 全額返金弊社の商品に自信を持っているから、失敗したら全額で返金することを保証します。弊社の商品でお客様は試験に合格できると信じていますとはいえ、不幸で試験に失敗する場合には、弊社はお客様の支払ったお金を全額で返金するのを承諾します。(
全額返金弊社の商品に自信を持っているから、失敗したら全額で返金することを保証します。弊社の商品でお客様は試験に合格できると信じていますとはいえ、不幸で試験に失敗する場合には、弊社はお客様の支払ったお金を全額で返金するのを承諾します。( ご購入の前の試用TopExamは無料なサンプルを提供します。弊社の商品に疑問を持っているなら、無料サンプルを体験することができます。このサンプルの利用を通して、お客様は弊社の商品に自信を持って、安心で試験を準備することができます。
ご購入の前の試用TopExamは無料なサンプルを提供します。弊社の商品に疑問を持っているなら、無料サンプルを体験することができます。このサンプルの利用を通して、お客様は弊社の商品に自信を持って、安心で試験を準備することができます。
